Parsing XML data with Python
This project is part of a series of articles around football analytics. Work is hosted on github: check it out!
Github linkIntroduction
Sometimes, you have to deal with semi-structured data such as XML (Extensible Markup Language, basically a way to store and organize data).
This is something you can find, typically when working with web services, e-commerce applications, but also databases.
It was the case on my current football analytics project: the matches table from the database I worked with had events stored as XML in dedicated columns (goals, corners, etc..).
for 1 match (1 row), there were N events, each stored as HTML/XML content in some of the table's columns.
In this post, I will show you how to parse that kind of data with a great python package: ElementTree.
Approach
1 - Markup language and tree structure
A markup language is a set of rules defining how content (text, images) presents itself.
HTML is a markup language, but also LaTeX and, of course, XML.
It can be structured (e.g. as a list, a table...) and formatted (e.g. bold).
First, this language is characterized by tags.
An example of tags would be:
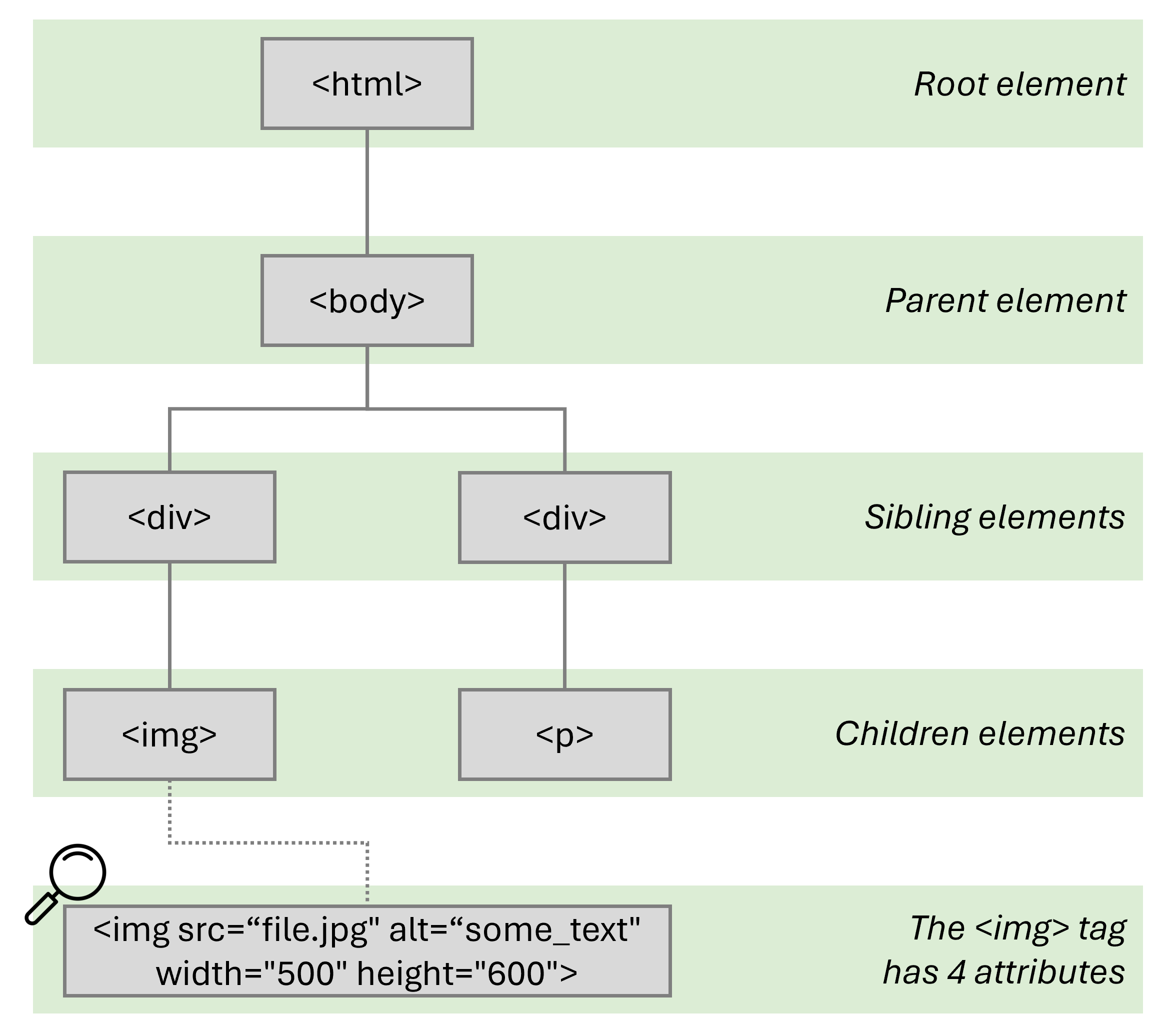
Second, Markup language have a tree structure, made of a root element, child elements, sibling elements and attributes.
The below example is highly simplified but should help you get a clearer understanding of how an element tree is structured.
- The <html> tag is the root element: there's nothing above
- The <body> tag is a parent element to the two <div> elements below
- The <div> tags are parent elements to the elements below, but also children - and sibling - elements to the <body> element
- The <img> and <p> children elements of the two <div> elements above
- The <img> tag has 4 attributes, which are the properties, stored as key-value pairs (src, alt, width, height)
2 - Analyzing the available data
When dealing with semi-structured data such as json, xml or html files, it can useful to use a code beautifier to analyze it easily.
In my case, I extracted the content of a few cells (intersection of a row and a column) and copy/paste these on Code Beautify.
That way, you can get a better understanding of how your data is structured and work with it.
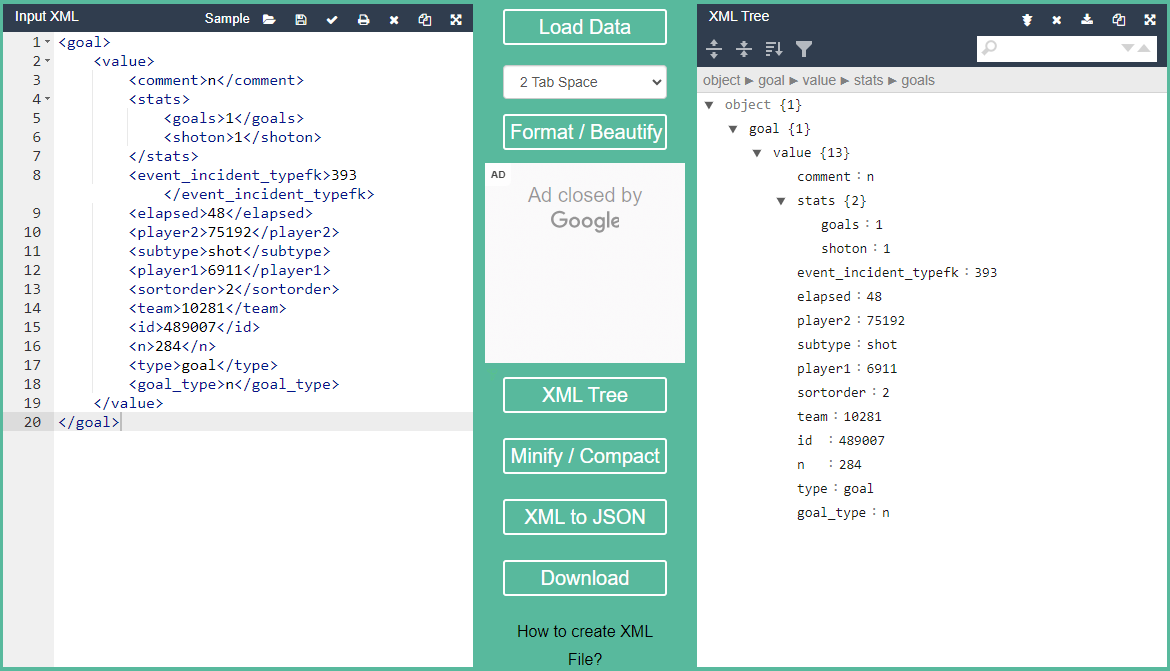
3 - Breaking down the data structure
By breaking down the above structure, it can be noted <goal> is the root element, <value> a parent element and tags such as <id> or <elapsed> are children and sibling elements.
Meaningful data to extract such as which player scored a goal (<goal>), which team is the player part of (<player1>), or when (<elapsed>) and how (<subtype1>) was the goal scored is now clearly identified.
Note that it is a good practice to test a few other values in this table and column, to ensure not to miss any valuable information when parsing it out.
3 - Parsing with Python and ElementTree
There are multiple ways to parse out data with XML ElementTree package.
In the notebook that I have referrenced, you have some examples of how to do it.
There are two main ways to work with this package, presented below.
A - Using XML ElementTree built-in functions
This is for vanilla use cases (simple, basic use cases).
If you don't really know what you need, or if your data set is not too voluminous, you can use the XML ElementTree functions.
Here are some examples of how to access the data that you need in an XML file.
# xml string = value at the intersection of the 4th row, column goal
xml_string = df.loc[4, "goal"]
# getting the root element
root = ET.fromstring(xml_string)
# getting the tag
root_tag = root.tag
# getting the attributes, if any
root_attrib = root.attrib
##########################################################
# looping over each child element in root
for child in root:
print(child.tag, child.attrib)
##########################################################
# looping over each element that has the tag "player1" (the goal scorer)
for element in root.iter("player1"):
print(element)
##########################################################
# children elements are nested: we use indexes to access these
root[1].tag
# if we want the grand children, we can use another index
root[1][1].tag
# etc..
root[1][1][0].tag
##########################################################
# accessing an element by it's value
searched_text = "37576"
for element in root.iter():
if element.text == searched_text:
print(element.tag, element.text)
B - Using XPath capabilities
Similarly to Regular Expressions (Regex), there exists XPath expressions, which are ways to navigate tree structures.
This is more suitable for non vanilla use cases (less standard/basic use cases).
The advantage of using XPath capabilities is that you can avoid scanning parts of a tree that you don't care about.
When you are dealing with large volumes of data, it may prove extremely useful to manage your workload properly.
Here are some XPath expressions examples. For more guidance, I suggest to use this great W3School resource on XPath syntax.
# All "player1" grand children from root element
# "." selects the current node (here: root)
# / selects from the current node
for element in root.findall("value"):
print(element.tag, element.text)
# Getting the goal scorer (player1) for all goals
for element in root.findall("value//player1"):
print(element.tag, element.text)
# Getting the goal scorer (player1) for the first goal only
for element in root.findall(".//value[1]//player1"):
print(element.tag, element.text)
4 - Parsing XML data out of a SQL column
In my case, there were multiple columns with meaningful data stored as events, in an XML structure: goals, corners, fouls, cards, etc..
Below is the script that I wrote to do it. Basically, it iterates over each row and creates a dictionary out of each event, extracting meaningful data out of it.
This can then be transformed into a dataframe, easier to manipulate with packages such as Pandas or NumPy.
i = 0
# creating an empty list to host event dictionaries
goal_events_dicts_list = []
# iterate over each row / match
for xml_string in df["goal"]:
root = ET.fromstring(xml_string)
# extracting elements below value
for element in root.findall("./value"):
# Access specific elements or attributes within each 'value' element
elapsed_time = element.findtext("elapsed")
elapsed_time_plus = element.findtext("elapsed_plus")
team = element.findtext("team")
goal_scorer = element.findtext("player1")
assist_player = element.findtext("player2")
event_type = element.findtext("event_incident_typefk")
type = element.findtext("type")
sub_type = element.findtext("subtype")
event_id = element.findtext("id")
# appending the list with dictionaries
goal_events_dicts_list.append({
"match_id": df["match_api_id"][i], # add current match ID to the dictionary
"event_id": event_id,
"event_type": type,
"event_sub_type": sub_type,
"team": team,
"goal_scorer": goal_scorer,
"assist_player": assist_player,
"elapsed_time": elapsed_time,
"elapsed_additional_time": elapsed_time_plus,
"event_type_key": event_type
})
i = i + 1
goal_events_df = pd.DataFrame.from_dict(goal_events_dicts_list)
Conclusion
Working with semi-structured data is not uncommon for data analysts. The key is to have a basic understanding of how the data is structured and using an appropriate parser. Here is a great resource to practice your XPath skills: XPath Playground.