Querying SQLite database with python
This project is part of a series of articles around football analytics. Work is hosted on github: check it out!
Github linkIntroduction
I have retrieved european football data from a Kaggle challenge. It was made available as a SQLite database, which is an embedded, server-less relational database management system.
In this post, I will show you how to connect to a SQLite database and query data with Python.
Approach
1 - IDE, database and Python DB API standards
In order to query data fronm a SQLite database (but also PostGreSQL or MySQL DBs) with Python, several steps are required:
- First, a connection is setup between the IDE and the DB, with a connect() method
- Second, a cursor is created. It is a python object that acts as intermediary between a DB connection and a SQL query
- Third, a SQL statement is passed through the cursor object
- Fourth, data is retrieved (via fetch).
After a few internet searches, I could not find a clear, universal definition for what a cursor object was and how useful it could be. For now, remember it is the intermediary between python and the database, with which you will send SQL statements and from which you will fetch results. This approach (using cursors) is common to many databases (PostgreSQL, SQLite, MySQL...) so it is good to be familiar with it.
Here is a schema found on, that summarizes things well.
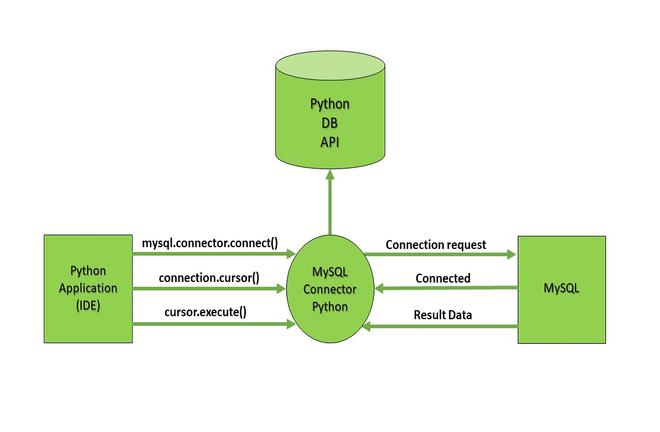
2 - Connection, profiling and test queries
Connection
Usually, when connecting to a DB with python, you build a connection string, which specifies the target data source and how you connect to it (by providing host, port, service name, username, password). Here, there are no such thing so the connection is extremely straightforward.
Data profiling
Working with a database tool such as DBeaver or Toad, you usually have access to a nice graphical interface that shows you the DB schema, its tables, its columns and a preview of the data.
As a data analyst, it is a good practice to always start by profiling your data, i.e. analyzing its content, structure and metadata.
Put simply: getting to know what you are dealing with.
When profiling a database, Here are a few things to look for:
- the list of available tables
- the number of rows in tables
- the list of columns in tables
- the relationships between tables
- the column data types
Below are some useful SQLite queries and a python code snippet to output a dataframe with column headers.
# import SQLite3 package
import sqlite3
import pandas as pd
# connect to DB
conn = sqlite3.connect(cfg.db_file)
# create a cursor object
cursor = conn.cursor()
# list tables
list_tables = "SELECT name FROM sqlite_master WHERE type='table'"
# list columns (position, name, type, number of non null values, default value, primary key indicator)
list_columns_from_table = "PRAGMA table_info(table_name)"
# preview a few rows of data
preview_table_sample = "SELECT * FROM table_name LIMIT 10"
# preview output as dataframe, with column headers
# with SQLite DB, columns aren't available by default
query_output = cursor.execute(preview_table_sample).fetchall()
column_names = [row[0] for row in cursor.description]
df = pd.DataFrame(data=query_output, columns=column_names)
3 - Querying data with pandas
Once you are more familiar with the data you are working with and that you have a clearer idea of what you want to extract out of your SQL database, you can proceed to the next step.
Pandas library works well with SQL databases, including SQLite. It is fairly easy to query data and output it as a dataframe, using the "pd.read_sql_query" function.
When writing SQL queries, here are a few good practices to have in mind:
- Avoid SELECT * statements: that will save network and disk resources and be easier to manage (in case of added columns, changed names, column's reordering)
- Comment your queries: it will be easier for you to maintain over time and it will make things simpler for your colleagues if they ever need to use your queries
- Indent your code: if you are lazy, there are free tools to help you, such as Code Beautify
- Use aliases: when querying multiple tables, it makes things easier to manage with aliases
# retrieving Real Madrid matches
get_rma_matches = """
-- team_api_id = 8633 is Real Madrid identifier
-- home and away matches involving Real Madrid will be queried
SELECT
m.id, m.country_id,
m.league_id,
m.season,
m.stage,
m.date,
m.match_api_id,
m.home_team_api_id,
ht.team_long_name AS home_team_name,
ht.team_long_name AS home_team_acronym,
m.away_team_api_id,
at.team_long_name AS away_team_name,
at.team_long_name AS away_team_acronym,
m.home_team_goal,
m.away_team_goal,
m.goal,
m.shoton,
m.shotoff,
m.foulcommit,
m.card,
m.cross,
m.corner,
m.possession
FROM Match m
LEFT JOIN Team AS ht
ON ht.team_api_id = m.home_team_api_id
LEFT JOIN Team AS at
ON at.team_api_id = m.away_team_api_id
WHERE (
m.home_team_api_id = 8633
OR m.away_team_api_id = 8633
)
"""
team_names_df = pd.read_sql_query(get_rma_matches, conn)
Conclusion
SQL and Python are very powerful, especially when combined together. For a future data analyst, it is important to be comfortable with both. Here is a great resource to get hands on experience with SQL: SQLZoo